

随着现代科技的迅猛发展,数据分析在各行各业的应用越来越广泛,特别是在博彩行业,数据分析已经成为不可或缺的工具,本文将探讨如何利用数据科学技术来分析和预测2024年香港今晚的特马开奖结果,并详细解释相关技术实现和具体步骤。
一、数据收集与预处理
数据收集是数据分析的第一步,对于香港赛马会的开奖结果,我们需要获取历史开奖数据,这些数据通常可以从官方网站或第三方数据提供商处获得。
1、数据源选择:
- 官方数据源:香港赛马会官网提供的历史开奖记录。
- 第三方数据源:一些专业的博彩数据网站也提供详细的开奖数据。
2、数据格式:
- 数据通常以CSV或JSON格式存储,便于后续处理。
- 每条记录包括日期、期数、开奖号码等信息。
3、数据清洗:
- 去除重复数据。
- 填补缺失值,例如使用均值、中位数或插值法。
- 标准化数据格式,确保所有数据项一致。
二、特征工程
特征工程是将原始数据转换为适合模型训练的特征集合的过程,这一步非常关键,直接影响到模型的性能。
1、时间特征:
- 日期特征:年份、月份、星期几等。
- 时间特征:小时、分钟等。
2、统计特征:
- 频率统计:每个号码出现的频率。
- 趋势分析:最近几期号码的变化趋势。
3、组合特征:
- 号码组合:将连续几期的号码进行组合,形成新的特征。
- 差分特征:计算相邻期数之间的差异。
三、模型选择与训练
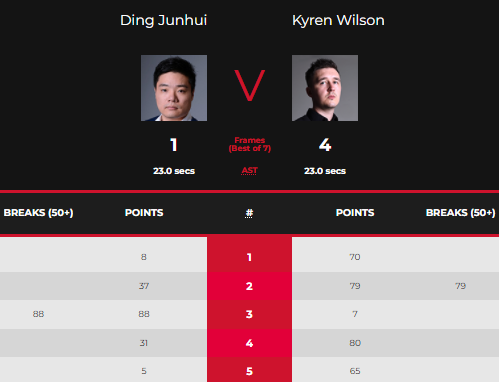
选择合适的模型并进行训练是数据分析的核心环节,常用的模型包括逻辑回归、决策树、随机森林以及深度学习模型等。
1、模型选择:
- 逻辑回归:适用于二分类问题,可以用于预测某一特定号码是否会出现。
- 决策树/随机森林:适用于多分类问题,可以预测多个号码的组合。
- 深度学习模型(如LSTM):适用于时间序列数据的预测。
2、模型训练:
- 数据集划分:将数据集分为训练集和测试集,通常按照7:3或8:2的比例划分。
- 超参数调优:通过网格搜索或随机搜索优化模型参数。
- 交叉验证:使用k折交叉验证评估模型性能,避免过拟合。
四、模型评估与优化
模型评估是确保模型泛化能力的重要步骤,常用的评估指标包括准确率、召回率、F1分数等。
1、评估指标:
- 准确率(Accuracy):预测正确的比例。
- 召回率(Recall):实际为正样本中预测为正的比例。
- F1分数:综合考虑准确率和召回率的指标。
2、混淆矩阵:
- 通过混淆矩阵可以详细了解模型在不同类别上的表现。
3、ROC曲线与AUC值:
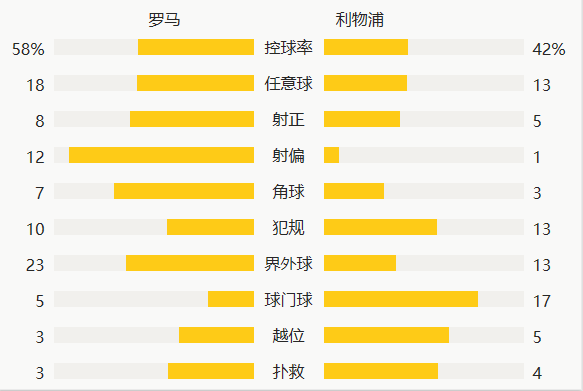
- ROC曲线展示了不同阈值下的真正率和假正率。
- AUC值衡量了模型的整体性能。
4、模型优化:
- 基于评估结果调整模型参数。
- 尝试不同的特征组合和模型架构。
- 使用集成学习方法提升模型性能。
五、结果可视化与解释
数据分析的结果需要通过可视化手段展示出来,以便用户理解和应用,常见的可视化工具有Matplotlib、Seaborn、Plotly等。
1、数据分布图:
- 直方图:展示号码出现的频率分布。
- 箱线图:展示数据的分布情况及异常值。
2、趋势图:
- 折线图:展示号码随时间的变化趋势。
- 热力图:展示号码之间的相关性。
3、预测结果:
- 散点图:展示预测值与实际值之间的关系。
- 误差图:展示预测误差的分布情况。
六、案例分析与实践
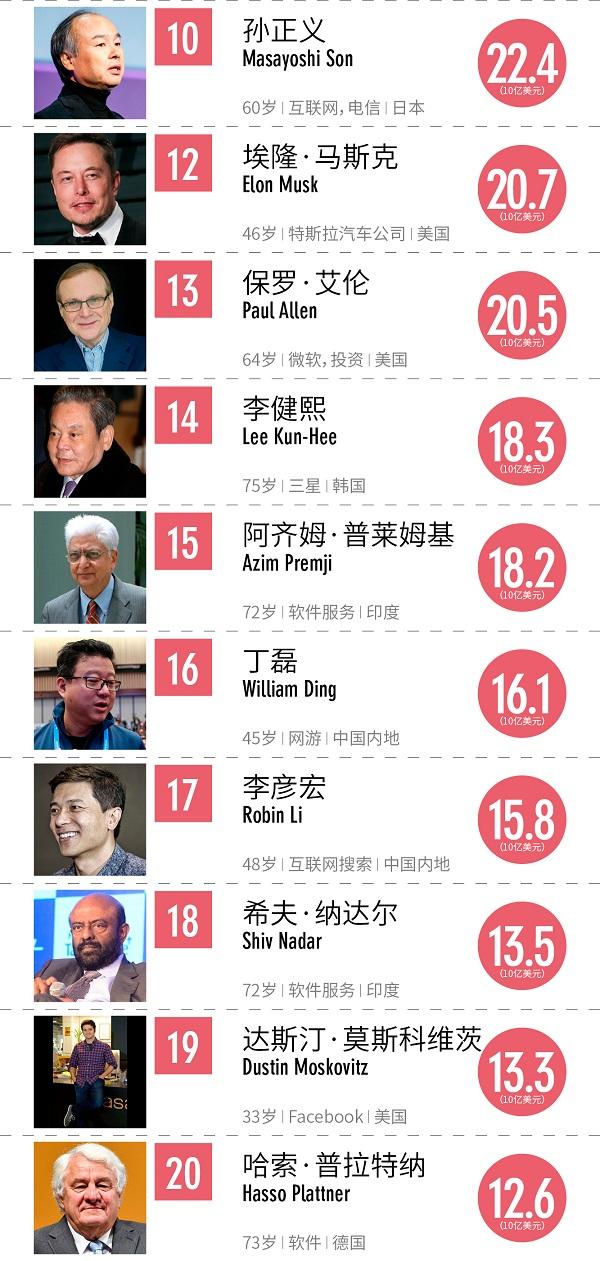
为了更好地理解上述流程,下面我们通过一个具体的案例来进行实践,假设我们已经收集到了过去100期的香港赛马会开奖结果数据。
1、数据收集:
- 从香港赛马会官网下载历史开奖数据,得到一个包含100条记录的CSV文件。
2、数据预处理:
- 使用Pandas库读取CSV文件,并进行初步的数据清洗。
import pandas as pd
df = pd.read_csv('horse_racing_data.csv')
df['date'] = pd.to_datetime(df['date'])
df.fillna(method='ffill', inplace=True)3、特征工程:
- 提取时间和统计特征。
df['year'] = df['date'].dt.year df['month'] = df['date'].dt.month df['day'] = df['date'].dt.day df['weekday'] = df['date'].dt.weekday df['hour'] = df['date'].dt.hour
4、模型训练:
- 使用随机森林模型进行训练。
from sklearn.model_selection import train_test_split from sklearn.ensemble import RandomForestClassifier from sklearn.metrics import accuracy_score, classification_report X = df[['year', 'month', 'day', 'weekday', 'hour']] y = df['winning_number'] X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42) model = RandomForestClassifier(n_estimators=100, random_state=42) model.fit(X_train, y_train)
5、模型评估:
- 评估模型性能。
y_pred = model.predict(X_test) print(accuracy_score(y_test, y_pred)) print(classification_report(y_test, y_pred))
6、结果可视化:
- 绘制预测结果的混淆矩阵。
import matplotlib.pyplot as plt
from sklearn.metrics import confusion_matrix
import seaborn as sns
cm = confusion_matrix(y_test, y_pred)
sns.heatmap(cm, annot=True, fmt='d')
plt.xlabel('Predicted')
plt.ylabel('Actual')
plt.show()七、总结与展望
通过上述步骤,我们利用数据科学技术对2024年香港今晚的特马开奖结果进行了分析和预测,虽然模型的表现还有待进一步优化,但已经展示了数据分析在博彩行业中的巨大潜力,我们可以结合更多的数据源和技术手段,不断提升预测的准确性和稳定性,希望本文能够为广大数据分析师和博彩爱好者提供一些有益的参考和启示。











 京公网安备11000000000001号
京公网安备11000000000001号 京ICP备11000001号
京ICP备11000001号
还没有评论,来说两句吧...