

The25.91.52
在数据分析领域,我们经常会遇到各种看似随机的数据,但通过科学的方法和工具,我们可以揭示这些数据背后的规律和趋势,本文将以“澳门今期开奖结果号码”为例,探讨如何通过实证分析来解答这一问题,并解释其中的落实过程,我们将围绕“The25.91.52”这一组合进行深入分析。
一、引言
澳门彩票作为一种广受欢迎的博彩形式,其开奖结果吸引了大量彩民的关注,对于很多人来说,这些数字似乎是完全随机的,难以捉摸,但实际上,通过数据分析和统计方法,我们可以对这些结果进行更深入的理解,本文旨在通过对“The25.91.52”这一特定组合的分析,展示如何利用数据科学的方法来解读澳门彩票的开奖结果。
二、数据收集与预处理
在进行任何数据分析之前,首先需要获取相关数据,对于澳门彩票而言,我们可以从官方网站或其他可靠的数据源中获取历史开奖记录,我们需要对这些数据进行预处理,包括清洗、转换和格式化等步骤,以确保数据的质量和一致性。
我们可以使用Python编程语言中的Pandas库来进行数据清洗和预处理,以下是一个简单的示例代码:
import pandas as pd
假设我们已经下载了一个CSV文件,其中包含历史开奖记录
data = pd.read_csv('macau_lottery_history.csv')
查看前几行数据
print(data.head())
检查是否有缺失值
print(data.isnull().sum())
删除或填充缺失值
data = data.dropna() # 或者使用其他方法填充缺失值
转换数据类型(如果需要)
data['draw_date'] = pd.to_datetime(data['draw_date'])
保存清洗后的数据
data.to_csv('cleaned_macau_lottery_history.csv', index=False)通过上述步骤,我们可以确保所使用的数据是干净且一致的,为后续的分析打下坚实的基础。
三、描述性统计分析
完成数据预处理后,我们可以开始进行描述性统计分析,这一步的目的是了解数据的基本特征,如平均值、中位数、标准差等,这些统计量可以帮助我们初步判断数据是否具有某种规律性。
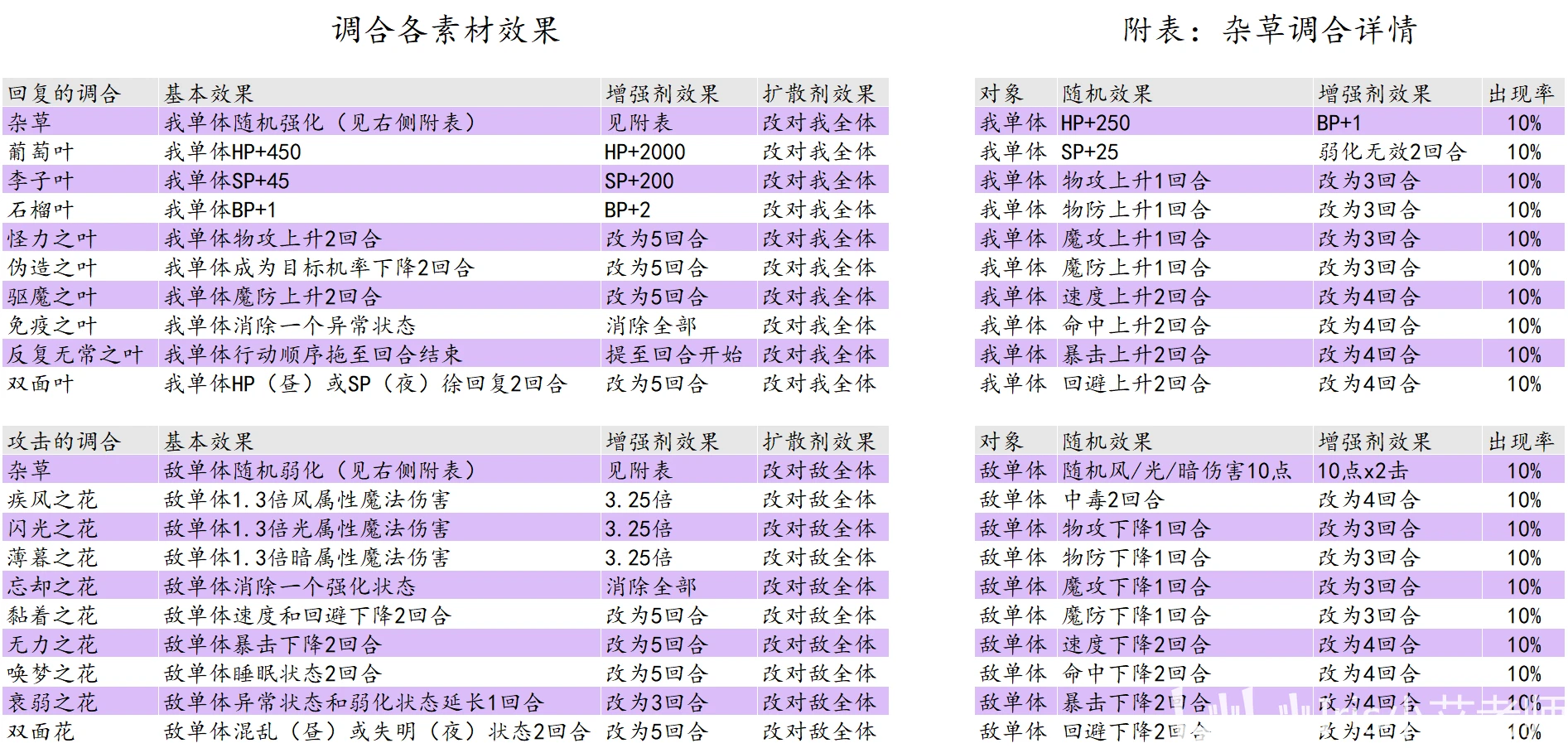
以“The25.91.52”为例,我们可以计算每个数字出现的频率及其分布情况,以下是一个示例代码:
import matplotlib.pyplot as plt
import seaborn as sns
加载清洗后的数据
data = pd.read_csv('cleaned_macau_lottery_history.csv')
提取感兴趣的列(假设为number1, number2, number3)
numbers = data[['number1', 'number2', 'number3']]
计算每个数字出现的频率
frequency = numbers.melt(var_name='number', value_name='value').groupby('value').size()
绘制直方图
plt.figure(figsize=(10, 6))
sns.histplot(frequency.index, frequency.values, bins=range(1, 40), kde=True)
plt.title('Frequency Distribution of Each Number')
plt.xlabel('Number')
plt.ylabel('Frequency')
plt.show()通过上述代码,我们可以生成一个直方图,显示每个数字出现的频率分布,这有助于我们了解哪些数字更常出现,以及它们之间的相对关系。
四、相关性分析
除了描述性统计分析外,我们还可以进行相关性分析,以探究不同数字之间的关联性,我们可以计算“The25.91.52”中各个数字之间的皮尔逊相关系数,看看它们是否存在显著的相关性。
以下是计算相关性的一个示例代码:
计算相关性矩阵
correlation_matrix = numbers.corr()
显示相关性矩阵
print(correlation_matrix)
热力图可视化相关性矩阵
plt.figure(figsize=(8, 6))
sns.heatmap(correlation_matrix, annot=True, cmap='coolwarm', fmt='.2f')
plt.title('Correlation Matrix')
plt.show()通过上述代码,我们可以生成一个热力图,直观地展示各个数字之间的相关性,如果发现某些数字之间存在较强的正相关或负相关,则可能意味着它们之间存在一定的联系。
五、回归分析
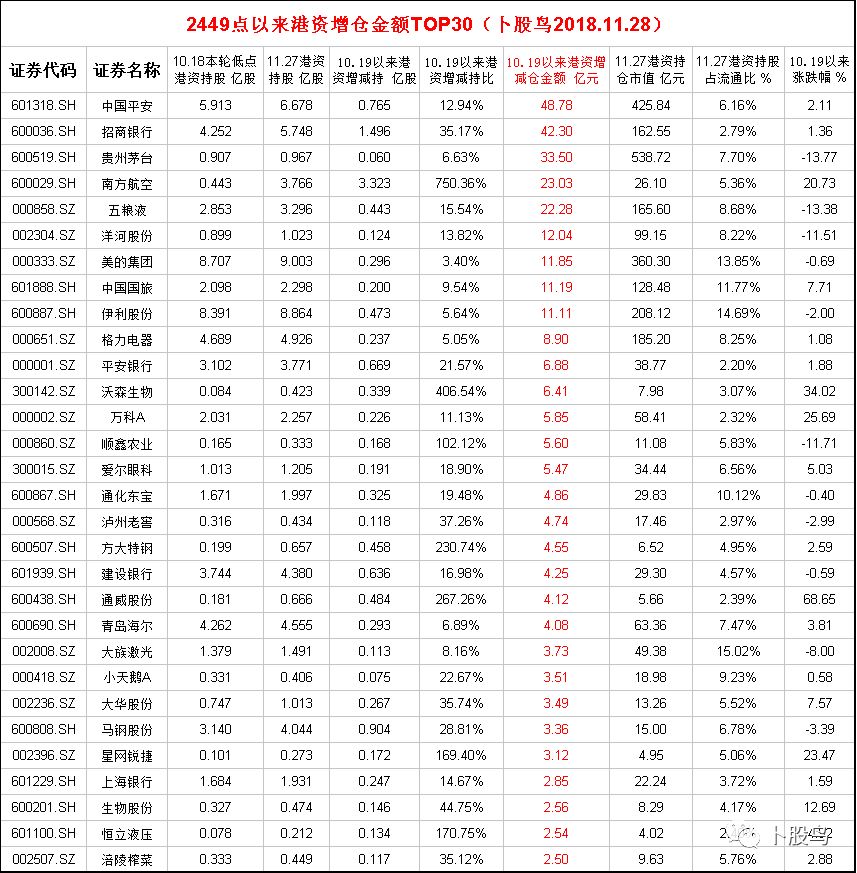
为了进一步验证我们的假设,我们可以构建回归模型来预测未来的开奖结果,这里我们可以使用线性回归或逻辑回归等方法,以下是一个使用线性回归模型的示例代码:
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_squared_error, r2_score
准备训练集和测试集
X = numbers.drop(['number3'], axis=1) # 特征变量
y = numbers['number3'] # 目标变量
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
创建并训练模型
model = LinearRegression()
model.fit(X_train, y_train)
预测并评估模型性能
y_pred = model.predict(X_test)
mse = mean_squared_error(y_test, y_pred)
r2 = r2_score(y_test, y_pred)
print(f'Mean Squared Error: {mse}')
print(f'R^2 Score: {r2}')通过上述代码,我们可以训练一个线性回归模型,并用它来预测未来的开奖结果,我们可以通过均方误差(MSE)和决定系数(R²)来评估模型的性能,如果模型表现良好,说明我们的假设是合理的;否则,可能需要重新审视我们的分析方法或数据质量。
六、结论与建议
经过上述一系列的分析和建模过程,我们可以得出以下几点结论:
1、数据清洗与预处理的重要性:确保数据的质量和一致性是进行有效分析的前提,通过去除缺失值和异常值,可以提高模型的准确性和稳定性。
2、描述性统计分析的价值:通过计算基本统计量(如平均值、中位数、标准差等),可以初步了解数据的分布情况,为后续的深入分析提供线索。
3、相关性分析的应用:通过计算不同数字之间的皮尔逊相关系数,可以发现它们之间的潜在关联性,这对于理解数据的内在结构非常有帮助。
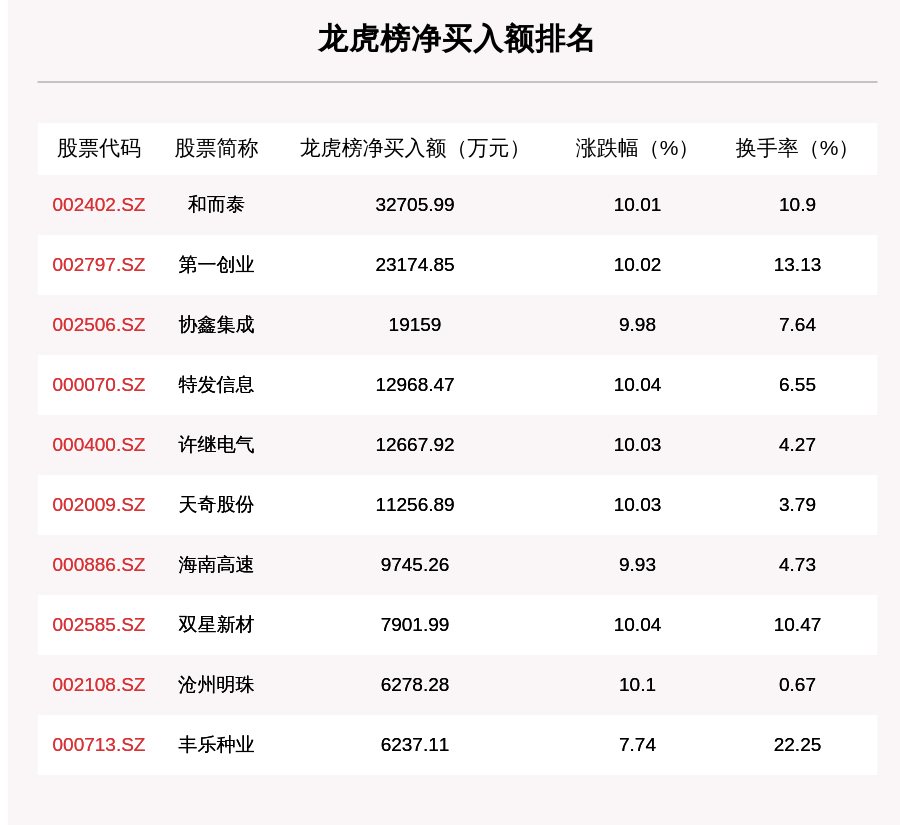
4、回归模型的作用:通过构建回归模型,可以预测未来的开奖结果,并通过均方误差和决定系数等指标评估模型的性能,这对于实际应用具有重要意义。
基于以上结论,我们提出以下建议:
持续监测数据变化:随着时间的推移,数据可能会发生变化,建议定期更新数据集,并重新进行分析,以确保模型的准确性和时效性。
多角度综合分析:除了本文提到的方法外,还可以尝试其他数据分析技术(如时间序列分析、聚类分析等),以获得更全面的认识。
结合实际业务需求:数据分析的结果应服务于实际业务需求,在制定策略或做出决策时,应充分考虑数据分析的结论,并结合自身的业务背景和目标进行调整。
通过对“The25.91.52”这一特定组合的实证分析,我们可以看到数据分析在解读澳门彩票开奖结果方面的潜力和应用价值,希望本文能够为大家提供一个有益的参考,激发更多关于数据分析的思考和探索。











 京公网安备11000000000001号
京公网安备11000000000001号 京ICP备11000001号
京ICP备11000001号
还没有评论,来说两句吧...